
Case Study Introduction#
This case study is intended to offer a unique blend of strategic thinking, technical know-how, and real-world impact. It prepares learners not only to understand the complexities of humanitarian logistics, but also to build and deploy data-driven solutions that have the potential to save lives and streamline global response efforts in the face of natural disasters.
This case study is ideal for students and professionals interested in operations research, data science, and optimization for social good. It provides a practical, end-to-end learning experience that encompasses business strategy, mathematical modeling, data analytics, and the use of technology to solve some of the most pressing global challenges facing the world today.
End-to-End Exploration of the Case Study:#
1. Business Context and Story#
This educational case study provides an in-depth exploration of the critical challenges ESUPS faces in managing the logistics of disaster relief at a global scale. The case begins by detailing the unique challenges and complexities of humanitarian logistics—such as unpredictable disaster locations, different relief needs, the need for centralized and standardized data, and the coordination of multiple stakeholders.
Students will understand how ESUPS aims to address these challenges through a data-driven approach and the development of an optimized pre-positioning strategy that enhances global preparedness.
2. Optimization Model and Data Analytics#
A key focus of this case study is the mathematical optimization model embedded within the STOCKHOLM platform. The study introduces students to the foundational principles of optimization, demonstrating how data analytics can be leveraged to make critical decisions about how much relief stock should be pre-positioned, and where.
Students will be given a subset of anonymized, real-world data that mimics the inputs used by ESUPS to run their models, allowing them to explore hands-on the complexities involved in developing and implementing optimization models that drive impactful outcomes in humanitarian contexts.
3. Hands-on Learning with a Jupyter Notebook#
To facilitate practical understanding, the case study includes a Jupyter Notebook, which guides students through the process of building, refining, and implementing an optimization model from scratch. This notebook serves as a step-by-step tutorial, from defining the problem and understanding the constraints to coding the solution and transitioning the model to a production environment. It also includes exploratory data analysis, model validation, and interpretation of the results, offering a holistic view of how data science and optimization techniques converge to solve real-world challenges.
4. Extending the Problem with Predictive Analytics#
Beyond the current scope, the case study provides avenues for students to extend their exploration using predictive analytics techniques. For example, students could be tasked with predicting future demand for specific relief items based on historical data, seasonal patterns, or the nature of past disasters. This section encourages critical thinking about how predictive models could be integrated into STOCKHOLM to improve the forecasting and allocation of resources, further optimizing response strategies and minimizing waste.
5. Impact and Implementation Summary#
The final section of the case study highlights the tangible impact of STOCKHOLM’s optimization capabilities on global humanitarian efforts. It outlines the real-world benefits observed, from reduced response times and lowered costs, to improved geographical coverage of relief supplies.
Additionally, it provides a roadmap for implementation, detailing the steps required to scale the optimization model, handle larger datasets, and integrate advanced analytics tools. Students will gain insights into the practical challenges of transitioning from a prototype model to a fully operational tool used by humanitarian organizations worldwide.
Diving Into the Case Study & Jupyter Notebook#
In this resource, we will take you through the end-to-end process of how ESUPS transformed from a simple idea into a global initiative that is reshaping disaster response logistics. We will delve into the crucial role that optimization plays in this transformation, demonstrating how ESUPS utilizes advanced algorithms to optimize the allocation and movement of disaster relief supplies.
Starting with the initial challenges faced by disaster relief organizations and the inefficiencies of traditional response methods, we will explore how ESUPS identified these gaps and developed a pioneering approach to pre-positioning resources.
The notebook will provide a detailed walkthrough of the optimization models that underpin ESUPS, offering a high-level explanation of the algorithms used, as well as their practical applications. You’ll see how ESUPS has integrated real-world data into these models to make informed decisions that improve response times and potentially save lives.
NOTE: While ESUPS is operating at a global scale, this case study will focus on building a model for only one country: Madagascar. This reduction in scope allows us to more clearly walk learners through a smaller version of the problem, and leverage either our limited-size Gurobi license (available to all learners), or our full Gurobi academic license (available to all currently affiliated students, instructors, and researchers) to solve the model.
To deepen your understanding, the notebook includes practical exercises that allow you to engage directly with the concepts. You’ll encounter multiple-choice self-assessment questions and hands-on code implementation problems designed to reinforce your learning and allow you to experiment with optimization techniques. These exercises are crafted to help you build confidence in applying the concepts without the pressure of graded responses.
Additionally, for those eager to dive deeper, the notebook features extension prompts that encourage you to think critically about how the underlying optimization problems could be adapted or expanded. These prompts are designed to challenge your creativity and problem-solving skills, enabling you to explore new ideas and potential improvements to the models.
Finally, we’ll pull back the curtain to reveal the production code used by ESUPS, written by experts in the field. You’ll have the opportunity to examine real-world code implementations that drive ESUPS’ operations, gaining insight into the practical considerations and best practices for creating fast, reliable, and maintainable code. This section will also explore alternative approaches and the reasoning behind key decisions made in the development process, providing you with a comprehensive understanding of how these algorithms transition from theoretical models to production-ready solutions. By the end of this notebook, you’ll have a solid grasp of how optimization, rather than machine learning, can be the most effective tool for solving complex logistical challenges, especially in high-stakes environments like disaster relief. You’ll also be equipped with the knowledge and practical skills to apply these techniques in your own projects, potentially making a significant impact in whatever field you choose to tackle.
The evolution of ESUPS from a spreadsheet repository to a sophisticated data-driven solution highlights the importance of efficient disaster relief logistics. However, while technology has significantly improved our ability to manage and allocate resources, it also presents new challenges. The task of optimizing supply distribution in real-time amidst unpredictable disaster scenarios is not just a logistical issue, but a complex data science problem. So, let’s dive into the technical challenges of prepositioning supplies together!
A Data Scientist’s Perspective#
As you begin to approach this problem, your first instinct might be to leverage machine learning (ML) tools. After all, the problem appears well-suited for machine learning: We have an implicit reward function in how well our allocation meets the demand for supplies, perhaps discounted by transit time and cost. We also have defined inputs (amount of supply and available warehouses) and outputs (where to store the supplies).
But just because the inputs and outputs are clear, doesn’t mean the program is easy to implement. Let’s look at what solving this with ML tools would look like in practice.
A Machine Learning Approach#
When considering (ML) approaches for complex problems, neural networks (NNs) are often one of the first tools that come to mind. This is understandable, as NNs are powerful function approximators capable of learning intricate patterns and relationships from large datasets. Given enough data and model capacity, they can approximate any function to arbitrary precision (a property known as the Universal Approximation Theorem).
However, for this case study on disaster relief in Madagascar, we face significant constraints. We have reliable data on only 64 disaster events, with each event characterized by limited features—primarily location, type, and impact. Additionally, our objective involves optimizing supply allocations for 13 different items across 27 warehouses. The challenge here is substantial: we must map a small, sparse dataset with limited features to a vast solution space, all while contending with a noisy reward function that makes it difficult to gauge success.
Challenges with Sparse Data and Neural Networks#
Sparse data is a notorious problem in machine learning. With only 64 data points, a neural network would struggle to generalize well, especially given the high-dimensional output space—13 items across 27 warehouses—resulting in 351 decision variables.
Now, there are several ways to deal with sparse data in ML, and you might have your own technique you want to try—and you absolutely should! If you find interesting results, we’d love to hear about them. But for now, let’s consider one of the most popular techniques: data interpolation.
Data interpolation attempts to create a probability distribution that closely mirrors real-world events, allowing us to sample synthetic data for training. Ideally, this synthetic data is representative enough that a neural network can learn from it. However, generating such a distribution is often as challenging as the original problem—especially when the relationships are highly complex or unpredictable. For instance, allocating goods based on past data might work, but predicting the location, type, and impact of future disasters introduces an additional layer of complexity.
Likely the first method that comes to mind when choosing an ML approach is neural networks, and for good reason. Neural networks are incredibly powerful tools that have transformed the modern world— they’re able to approximate any function to arbitrary precision, provided they are large enough and have enough data. However, in this case study, we’ll be drilling down on disasters in Madagascar, for which we only have reliable data on 64 events. To make matters even more complicated, each disaster is characterized by limited information—mainly location, type, and impact.
Optimization: A Structured Approach to the Solution Space#
After exploring the challenges of using neural networks to navigate the vast solution space, it’s clear that the sheer size of possible allocations makes a purely machine learning approach inefficient for this problem. Neural networks, while powerful, rely on sampling from a solution space that is inconceivably large, then gradually improving through incremental updates. This approach can be highly ineffective when dealing with a combinatorial explosion of possibilities, as we saw with our earlier calculations.
Instead, when faced with such a well-defined problem—where we know the objective function, inputs, outputs, and constraints—a more structured approach through optimization becomes not only viable, but advantageous. Optimization techniques are specifically designed to handle these kinds of problems efficiently by applying systematic mathematical logic, rather than heuristic sampling.
In this case, our problem is clearly formulated:
Objective Function (What we want to minimize):
Minimize the travel time or cost required to meet demand by pre-positioning supplies.
Constraints (how we can change the variables):
Ensure demand is met without exceeding available supplies.
Unlike neural networks, optimization frameworks don’t blindly sample solutions from a vast space. Instead, they apply logical methods to systematically explore and reduce the search space, ultimately providing a set of potential optimal solutions. This not only increases efficiency, but also provides clarity and insight into why a particular solution is optimal, which is invaluable for decision-making and explanation.
The Simplex Method#
The simplex method is a powerful algorithm for solving linear programming problems, which involve optimizing a linear objective function subject to linear constraints. . Based on geometric principles, it efficiently navigates the feasible region—a polyhedron formed by the intersection of these constraints—to find the optimal solution at one of its vertices or “corner points.” In linear programming, the optimal solution is guaranteed to be at a vertex, because the objective function improves as we move along the edges of the polyhedron until we can’t improve any further.
To visualize this, imagine a two-dimensional feasible region shaped like a polygon on a graph. Each point within this polygon represents a possible solution that satisfies the constraints. The simplex method moves from one vertex to another along the edges of this polygon, evaluating the objective function at each corner point. This process is efficient because it doesn’t require checking every possible point within the feasible region.
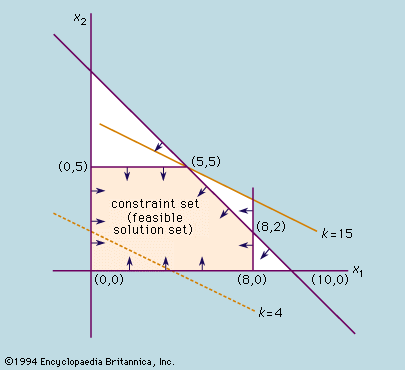
For example, if you’re trying to maximize your enjoyment by purchasing hotdogs and soda with a limited budget, you’d intuitively spend all your money, fully utilizing your budget constraint. The optimal solution occurs at the point where your spending exactly meets your budget limit—one of the vertices of the feasible region where the constraints are tight or binding.
In the context of pre-positioning supplies for disaster response, each allocation affects the total transit time. The goal might be to meet demand with the minimum possible transit time, which requires allocating supplies so that the constraints are fully utilized—providing just enough to meet each warehouse’s demand without surplus. This means the optimal solution will be at a vertex where the supply and demand constraints are exactly satisfied.
In transportation problems like ours, with whole-number supplies and demands, we’re distributing indivisible units like buckets or hygiene kits. Since the suppliers have integer quantities to offer and the consumers require integer quantities to receive, the shipments must also be in whole numbers to exactly meet these needs. Fractional shipments wouldn’t satisfy the exact integer requirements, nor would they make practical sense when items can’t be divided.
Geometrically, because the constraints are defined by integer values, the feasible region is a polyhedron whose vertices correspond to integer solutions. The simplex method, by moving along the edges of this integer-defined polyhedron, often arrives at integer solutions naturally. The constraints dictate that the total shipped from each supplier equals their supply and the total received by each consumer equals their demand, both of which are integers. This setup leads to shipment amounts that are integers, because only whole units can satisfy both the supply and demand without leaving any fractions unaccounted for.
This approach offers a clear advantage: Instead of searching through a massive number of possible solutions within the feasible region—as might be necessary with other methods—the simplex method only needs to evaluate a finite number of vertices, one of which will be the optimal solution. In transportation problems with integer constraints, it often provides optimal integer solutions without the need for additional techniques, like the branch and bound method. This makes the simplex method both effective and practical for scenarios where exact quantities are essential.
An Advancing Field#
Optimization has taken a backseat with the rise of machine learning and Big Data. But if you think back to your courses, you’ll remember that both fields share many of the same mathematical roots. Many core ML concepts, such as gradient descent, evolved from numerical optimization techniques like Newton’s method. This is relevant to our discussion because, even though optimization might seem less flashy compared to the latest ML algorithms, it is experiencing a resurgence.
Recent advancements in solvers and algorithms have made optimization more powerful and easier to use, allowing it to tackle complex, large-scale problems that were previously out of reach. There are also many free educational resources available to get problem solvers up and running with optimization, making it more accessible than ever before—check out Gurobi’s leanrning resources page for just some of the educational materials openly available to learners.
All of this means that optimization is becoming an essential tool for decision-making in various industries, from logistics to finance.
The type of mathematical optimization model this case study looks at is a linear program (LP), which was described above. But there are many other flavors of models, which are more complex than LPs and can help modelers represent extremely complex problems mathematically. If you are curious about what this means for real-life applications, take a look below at some of the examples!
A Few Real-World Examples:#
1. Mixed-Integer Linear Program (MILP):#
MILPs are widely used in logistics and supply chain optimization. A real-world example is vehicle routing for delivery companies like UPS or FedEx, where the goal is to minimize the total distance traveled or delivery time, while meeting constraints such as vehicle capacity, delivery time windows, and route restrictions. Advanced MILP solvers allow these companies to dynamically adjust routes in real-time, respond to traffic conditions, and make last-minute changes. This type of optimization is also critical in energy management, such as optimizing the scheduling of power generation plants to meet fluctuating demand, while minimizing costs and adhering to regulatory and operational constraints.
2. Mixed-Integer Quadratic Program (MIQP):#
MIQPs find applications in financial portfolio optimization, where the goal is to maximize returns while minimizing risk. In this context, the quadratic term represents the risk (variance or covariance of asset returns), and the integer constraints can represent decisions, like “buy or don’t buy” a particular asset, or “fully divest from one sector.” Hedge funds and asset management firms use MIQP to optimize asset allocation, considering various market scenarios and investment constraints. The ability to handle complex quadratic relationships between variables makes MIQP suitable for any industry where risk management and trade-offs are involved, such as in optimizing communication networks and antenna placements.
3. Mixed Integer with Quadratic Constraints Program (MIQCP):#
MIQCPs are used in engineering design and manufacturing—for example, to optimize the layout of a factory floor or the design of an aircraft wing. The quadratic constraints might represent aerodynamic properties or stress limits, while integer variables can represent decisions like the number of machines or parts used. In the pharmaceutical industry, MIQCP can help optimize drug formulation processes by considering a wide range of constraints like stability, release rates, and production costs. The combination of integer and quadratic constraints allows for highly tailored solutions that can significantly reduce costs and improve performance in complex industrial systems.
The Power of Mathematical Optimization#
In addition, optimization programs like Gurobi offer powerful tools such as pre-solve, which can significantly simplify models before they are solved. For instance, the country-level ESUPS model we’re working on would typically require 812 iterations of the simplex algorithm to reach a solution. However, with pre-solve enabled, we can reduce that number to just one iteration! This kind of optimization not only saves time, but also dramatically reduces computational costs.
Imagine the impact if large language models (LLMs) like ChatGPT could suddenly use 23% fewer computational resources to train and run, or if their size could be reduced by two orders of magnitude while maintaining the same level of performance. This would save hundreds of millions of dollars and lead to a surge in locally hosted LLMs. Similarly, in the field of optimization, problems that were once considered too large or too complex to solve are becoming increasingly feasible each year.
Just like machine learning algorithms, the mathematical foundations behind optimization techniques can be quite intricate, and certainly justify the rigor of PhD programs. However, as with popular libraries like PyTorch, TensorFlow, and XGBoost, you don’t need to master all the underlying math to use these tools effectively—it’s more important to know how to set up the problem correctly.
For the rest of this notebook, we’ll focus on how to formulate optimization problems and use accessible tools like Gurobi to solve them.